Deep Learning Approach to Manage Household Waste
Household waste, or residential waste, is the discarded material produced by individuals and families in their homes, including food scraps, paper, plastics, glass, metal, and electronics. These waste generated on a daily basis varies significantly, influenced by various factors such a location, population density, and lifestyle. The global average of municipal solid waste generation per capita is 0.74kg per day, but it can be as high as 2.1kg per day in high-income countries like the United States. The amount of household waste generated every day is significant, and proper waste management is crucial for reducing its negative impact on the environment and human health.
Proper identification of household waste through segregation and understanding what can be recycled can help in managing it effectively, reducing waste, reusing items, and contributing to a sustainable future. With advancements in machine learning and computer vision technology, various waste classification techniques have been developed. These techniques use cameras and sensors to identify and sort different types of waste, such as plastic, paper, metal, glass, and organic materials, using deep learning algorithms.
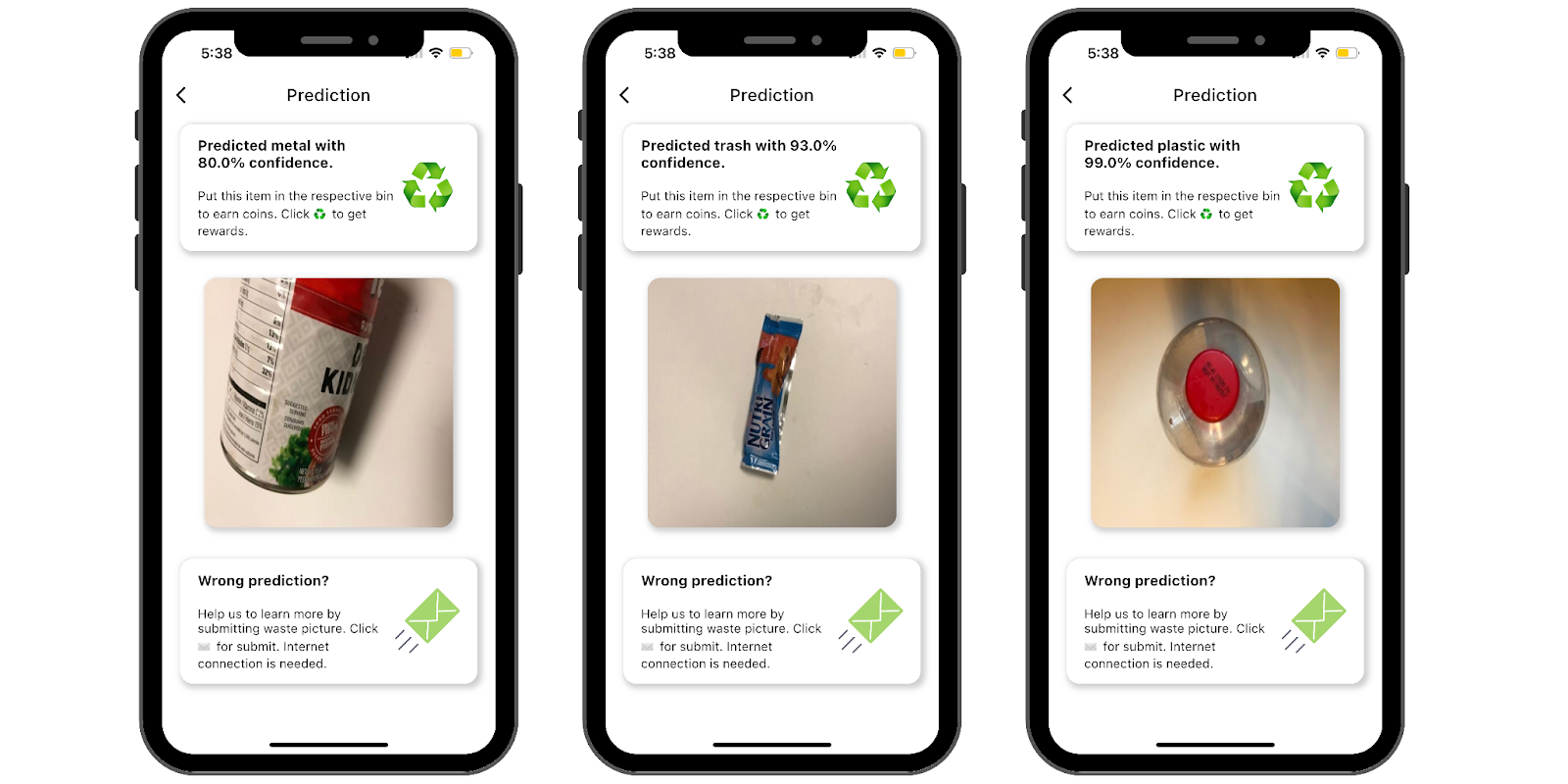 Identifying waste
Identifying waste
Creating a waste classification model for a mobile app
Here is a general procedure for creating a machine learning model along with an example of DWaste app:
Define the problem: Define the problem and the goal you want to achieve. Identify the type of machine learning problem it is (supervised / unsupervised / reinforcement learning) and the type of data you have( structured / unstructured).
Inefficient and ineffective waste management practices are a widespread problem that can be addressed through the automation of waste sorting processes. The household waste can be identified and classified based on their images, allowing for the implementation of appropriate waste management strategies based on their location and available resources.
Machine learning algorithms such as convolutional neural networks (CNNs), decision trees, or support vector machines (SVMs) can be applied to learn from the label waste dataset and accurately predict the correct label (type of waste) for new, unseen inputs.
- Gather and preprocess data: Identify and gather data that is relevant and sufficient to solve the problem, and then clean the data, remove duplicates, handle missing values, and transform it as necessary.
For our purpose, we will be using an existing trashnet dataset that consists of 2527 images and spans six classes: glass, paper, cardboard, plastic, metal, and trash. Here, the pictures were taken by placing the object on a white poster board with natural lights via different iphones: iPhone SE, iPhone 5S and iPhone 7S. It’s been resized to 512 x 384 and annotated by experts.
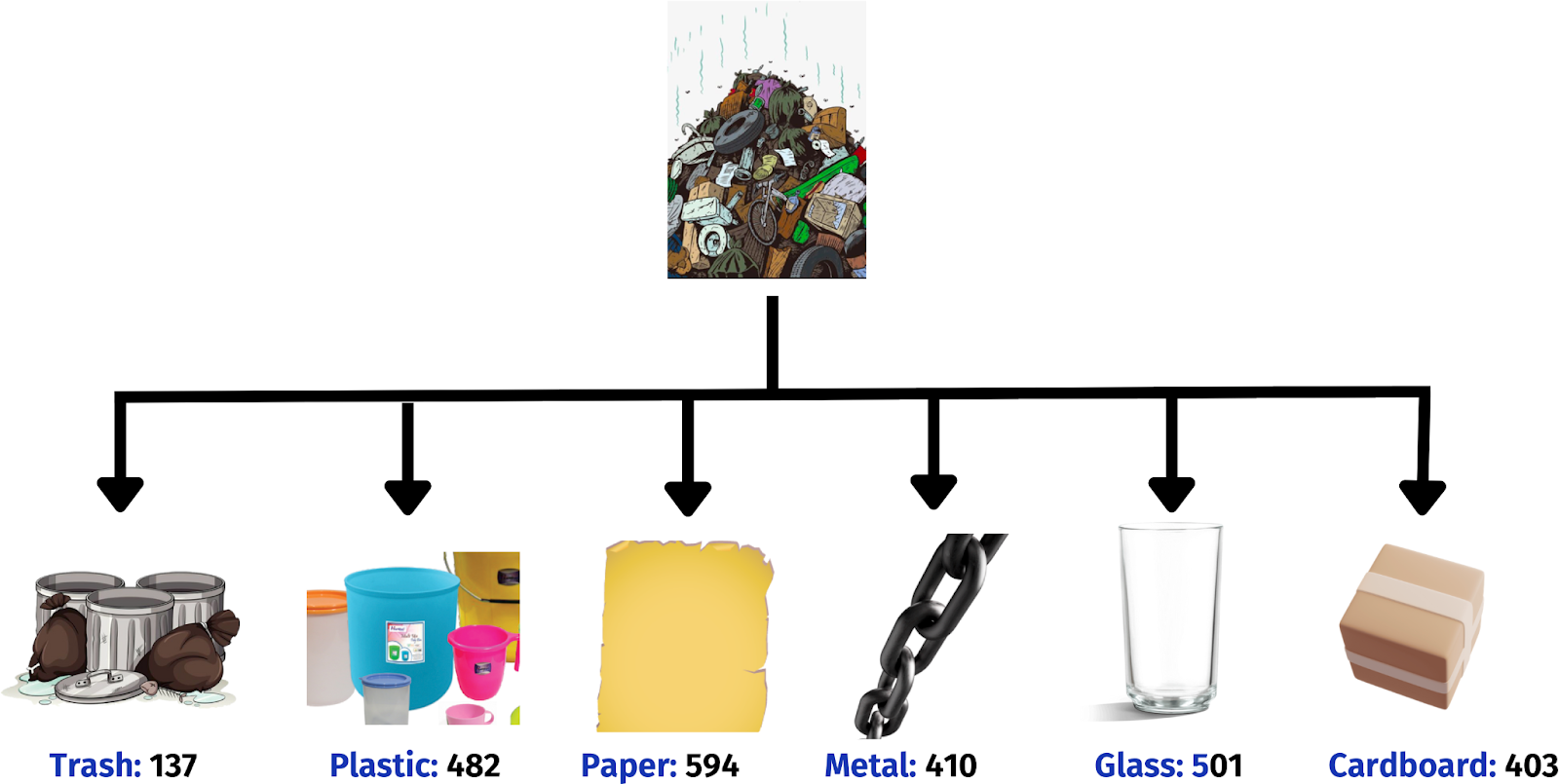 Dataset composition
Dataset composition
- Split data: Separate the data into three sets: training, validation, and testing. Use the training set to train the model, the validation set to evaluate and tune the model, and the testing set to assess the model’s performance.
Datasets are divided into training, validation, and testing sets. In the training set, we used 60% of the images, followed by 13% on testing and 17% on validation set. The training set to train the model, the validation set to evaluate and tune the model, and the testing set to assess the model’s performance.
- Choose a model: Identify the best model based on the data and the problem. This can be accomplished through research, experimenting with different models, and acquiring domain knowledge.
Various techniques and algorithms can be used to classify different types of waste. For our model we will be using some of the state of the art deep learning models: MobileNet, InceptionV3, ResNet50, InceptionResNetV2, MobileNetV2, Xception as they have seen effective in the classification problem or has been in waste classification before.
- Train the model: Train the selected model using the training set. It involves configuring hyperparameters, defining a loss function, and using an optimization algorithm to minimize the loss.
We will be training these models with the same settings. We will be using categorical cross-entropy as the loss function and Adam as an optimizer. Global average pooling is applied in the final convolutional layer for the classification task to generate one feature map per category. This technique helps to minimize overfitting and improve the model’s performance.
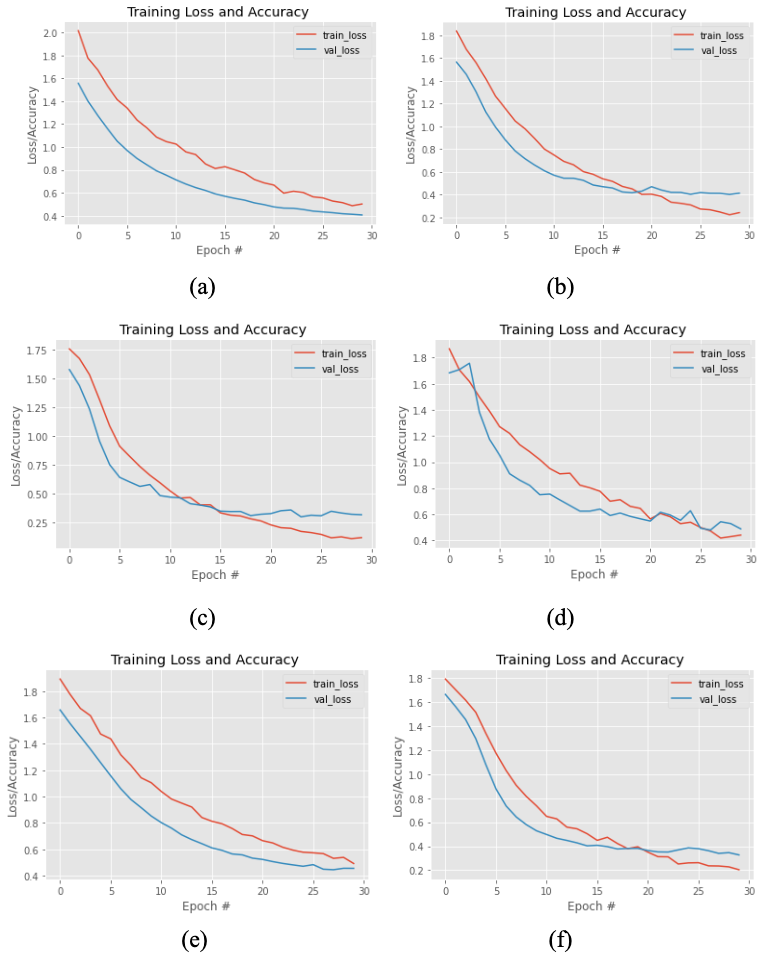 Training Loss and Accuracy graph of (a) MobileNet (b) Inception V3 © InceptionResNet V2 (d) ResNet50 (e) MobileNet V2 (f) Xception models with given datasets
Training Loss and Accuracy graph of (a) MobileNet (b) Inception V3 © InceptionResNet V2 (d) ResNet50 (e) MobileNet V2 (f) Xception models with given datasets
- Evaluate the model: Evaluate the model’s performance on the validation set. This helps identify potential problems with the model, such as overfitting or underfitting.
The performance of the model is then evaluated by using Accuracy Score and F1 Score on the validation set. These metrics provide clear indications of the model’s performance in predicting the correct class labels. Accuracy Score measures the proportion of correctly predicted instances out of the total number of instances in the dataset, while F1 Score is a harmonic mean of precision and recall. Precision and recall are two metrics that are taken into account by F1 Score, making it suitable for imbalanced datasets where one class is more prevalent than the other.
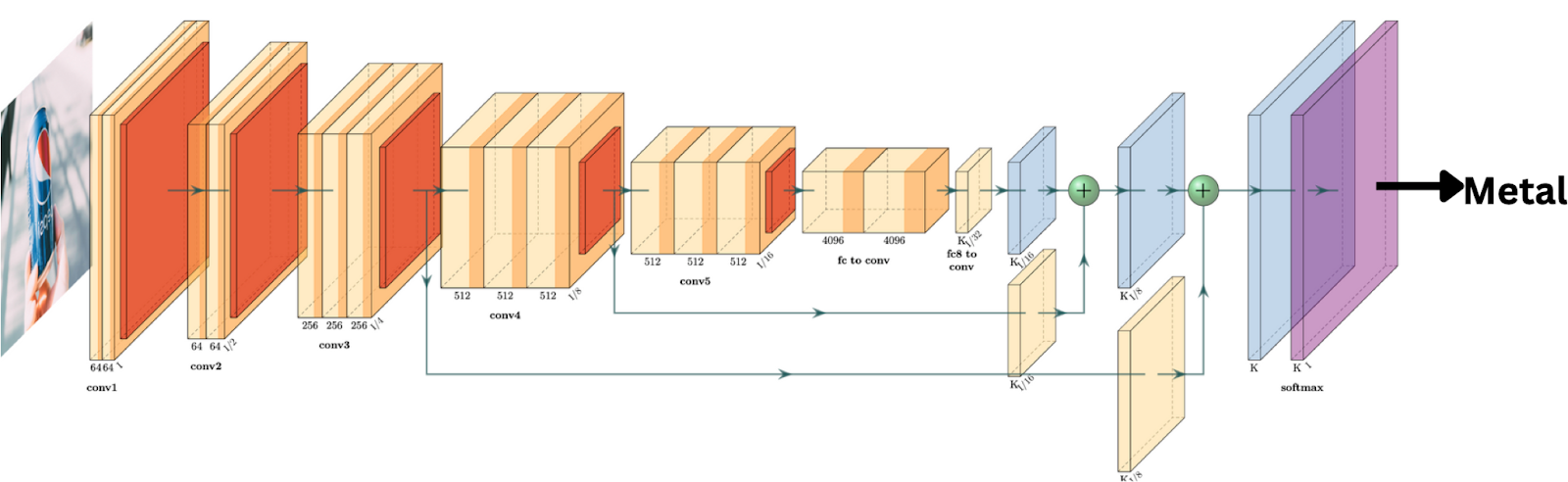 Neural Network Classifying Waste
Neural Network Classifying Waste
- Fine-tune the model: Fine-tune the model’s hyperparameters to optimize its performance on the validation set. This may require iterative experimentation with various values for the hyperparameters or utilization of advanced optimization techniques to achieve the best possible results.
Additional three dense layers are employed to improve classification accuracy, and dropout is used to prevent overfitting. Softmax function is used as an activation function to convert output values into probabilities.
- Test the model: Test the final model on the testing set to evaluate its performance on new, unseen data.
The models are tested again on the testing set to evaluate its performance on new, unseen data. Their accuracy and f1-score are measured and a conclusion is drawn. And found out that Xception and InceptionResNetV2 have higher accuracy.
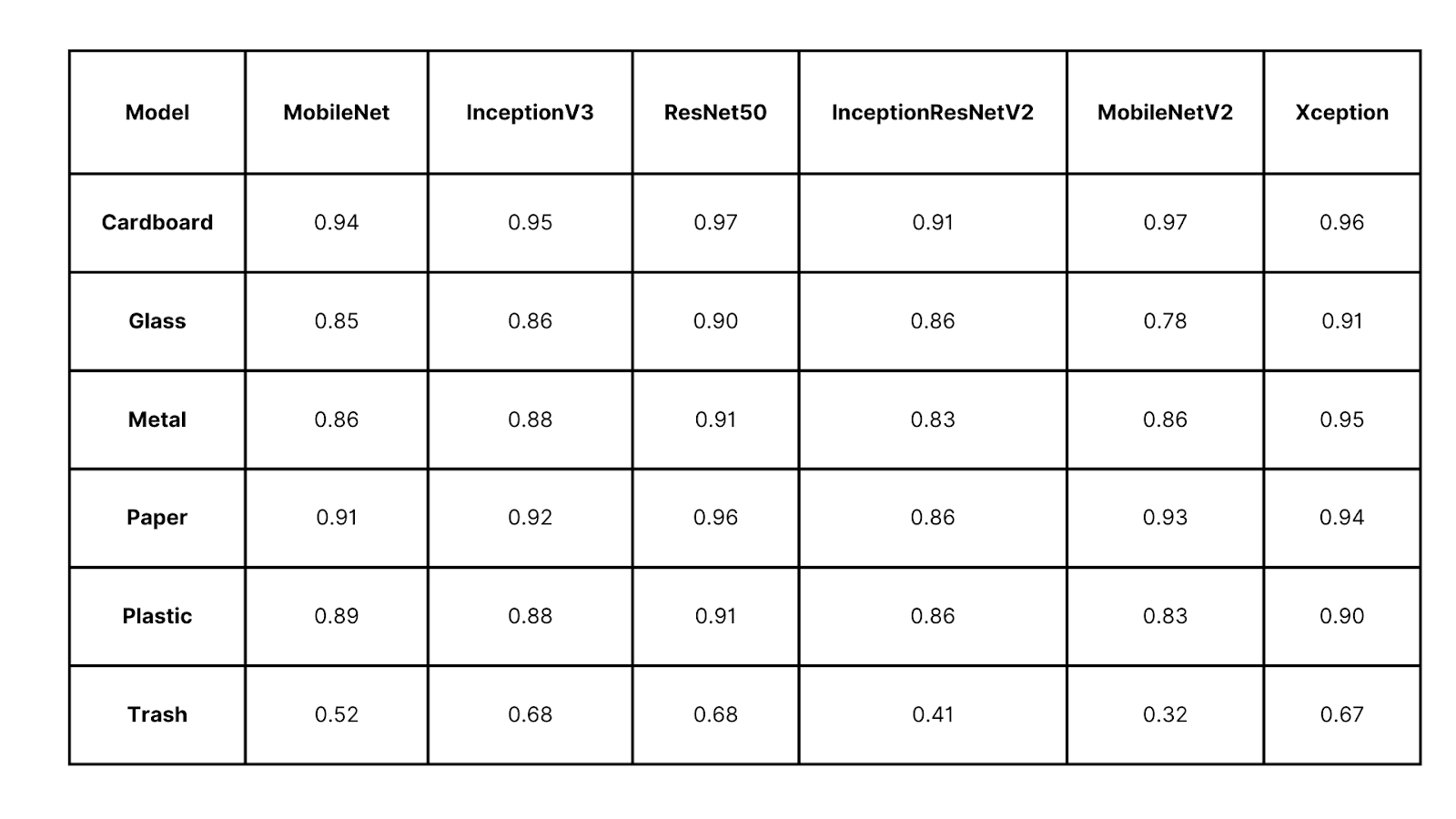 F1- Score of deep learning models for each class in a given datasets
F1- Score of deep learning models for each class in a given datasets
- Deploy the model: Deploy the model in a real-world application or system. This may involve integrating the model with other software, hosting the model on a cloud platform, or creating a user interface for interacting with the model.
The created model can be hosted in server and made available through RESTful api. By doing so, other applications and services can easily integrate with the model and use its predictions to enhance their functionality. It is a common practice in modern software development, where ML models are treated as micro services that can be accessed through APIs. The RESTful api for our model can be found here.
Besides this, we can also embed the model in our app. In the DWaste case, the model was embedded after converting it to a .tflite file. TFLite is advantageous because it can run machine learning models on mobile and embedded devices with limited resources, has a small size and fast loading time, and is compatible with multiple programming languages and platforms. It also allows for easy integration with other TensorFlow models, making it a versatile tool for developers.
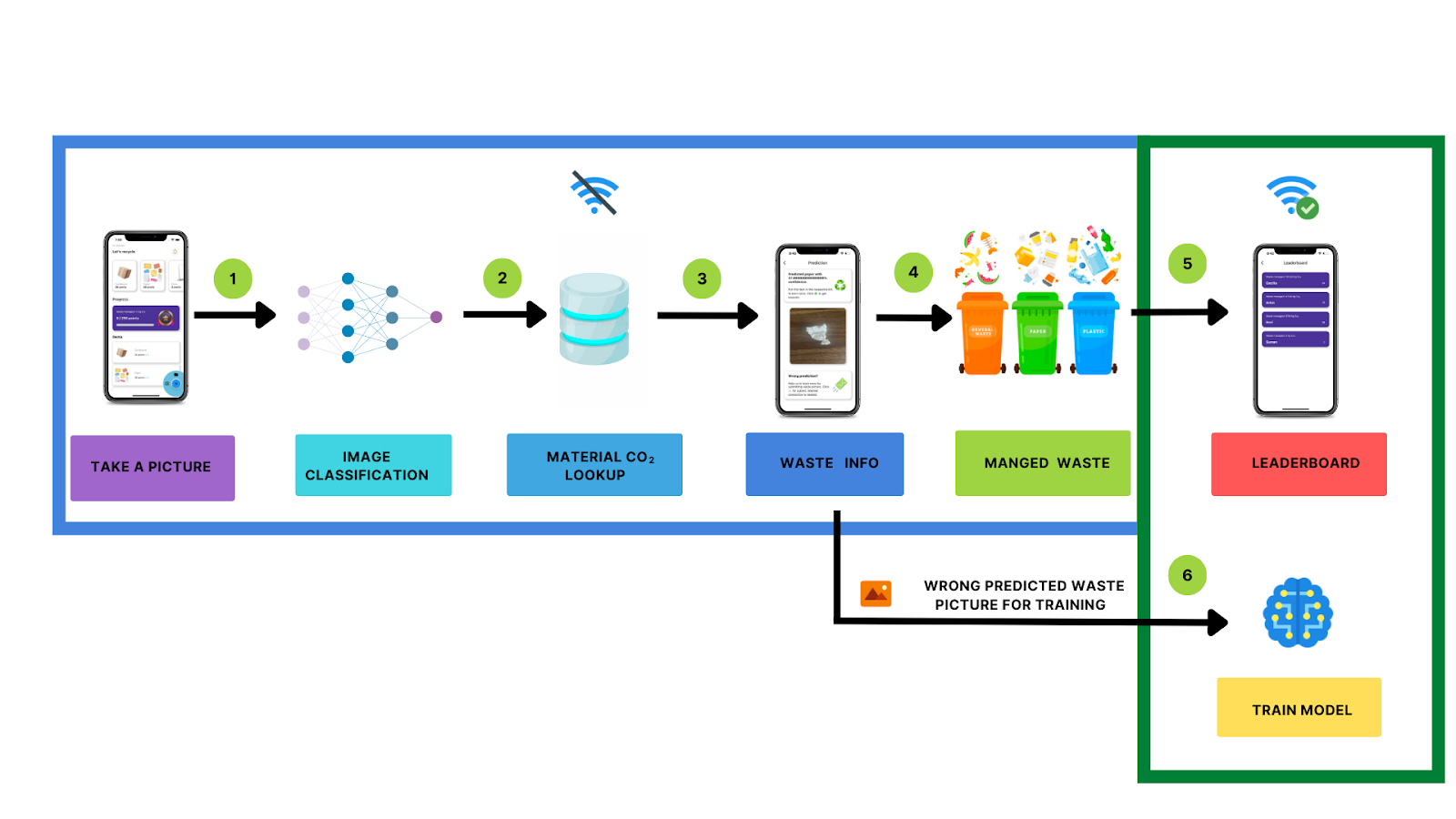 Process flow of DWaste App
Process flow of DWaste App
- Monitor and maintain the model: Continuously monitor the model’s performance and update it as needed to ensure its accuracy and relevance over time.
Classifying waste based on image is a challenging task, as the composition of materials varies the recyclability or compostability. Also, the waste comes in various shapes and sizes, and can be affected by the local recycling center capabilities. So, there should be a place for monitoring and improvements, one can collect feedback to see how well its classifying, train more data and use state of art tools and technologies.
Conclusion:
Machine learning is a powerful tool that can help to improve waste management practices in various ways, including automating waste sorting, accurate identification and categorisation of waste, and promoting sustainable approaches to waste management. By leveraging machine learning models, it is possible to achieve effective household waste management and reduce the amount of waste sent to landfills. Ultimately, this can help to promote recycling and reuse, leading to a more sustainable future. Among the various methods, we have demonstrated the development of a waste classifier using deep learning and its implementation by taking a DWaste app as an example.
Here are the locations where you can find the different components of the DWaste project: The source code for the app is available here, the research paper can be found at this url, and the machine learning component is located here.
Cheers, thanks for reading! 😊
Sources:
- https://github.com/garythung/trashnet
- World Bank. (2018). What a Waste 2.0: A Global Snapshot of Solid Waste Management to 2050. https://openknowledge.worldbank.org/handle/10986/30317
- U.S. Environmental Protection Agency. (2021). Municipal Solid Waste. https://www.epa.gov/facts-and-figures-about-materials-waste-and-recycling/national-overview-facts-and-figures-materials#NationalPicture
Published : Apr 4, 2023
Household Waste
Deep Learning
Mobile App
Sustainiability